
Subscribe to our daily and weekly newsletters for the latest updates and content from the industry’s leading AI site. learn more
Microsoft isn’t resting its AI success on the merits of its partnership with OpenAI.
No, far from it. In fact, the company that is often known as Redmond in its headquarters in Washington State today came out swinging and released three new models in its Phi version of language / multimodal AI.
The three new Phi 3.5 models include the 3.82 billion Phi-3.5-mini-instruct, the 41.9 billion Phi-3.5-MoE-instruct, and the 4.15 billion parameter Phi-3.5-vision-instruct, each designed to be beginner/fast. imagination, critical thinking, and vision (analyzing pictures and videos) respectively.
All three versions are available for developers to download, use, and customize Hugging Face under Microsoft’s MIT License which allows commercial use and modification without restrictions.
Surprisingly, all three models also boast close to top performance in a number of third-party tests, even beating other AI processors including Google’s Gemini 1.5 Flash, Meta’s Llama 3.1, and even OpenAI’s GPT-4o in some cases. .
That action, combined with an open license, has people praising Microsoft on social media X:
Let’s gooo.. Microsoft just released Phi 3.5 mini, MoE and vision with 128K, multiple languages & MIT license! MoE beats Gemini flash, Vision competes with GPT4o?
> Mini with 3.8B parts, beats Llama3.1 8B and Mistral 7B and competes with Mistral NeMo 12B
– Vaibhav (VB) Srivastav (@reach_vb) August 20, 2024
>… pic.twitter.com/7QJYOSSdyX
Good for @Microsoft to get the best results with the newly released phi 3.5: mini+MoE+vision ?
The Phi-3.5-MoE beats the Llama 3.1 8B across benchmarks
Of course, Phi-3.5-MoE is a 42B parameter MoE with 6.6B activated during generation.
And the Phi-3.5 MoE exceeds… pic.twitter.com/9d4h5Q5p7Z
– Rohan Paul (@rohanpaul_ai) August 20, 2024
How the hell is Phi-3.5 possible?
Phi-3.5-3.8B (Mini) somehow beats LLaMA-3.1-8B..
(trained on 3.4T tokens only)Phi-3.5-16×3.8B (MoE) somehow beats Gemini-Flash
(trained for 4.9T tokens only)Phi-3.5-V-4.2B (Vision) somehow beats GPT-4o
(trained for 500B tokens)Why? Laugh pic.twitter.com/97gmx1CsQs
— Yam Peleg (@Yampeleg) August 20, 2024
Let’s review each new brand today, in brief, based on their release notes posted to Hugging Face
Phi-3.5 Mini Instruction: Optimized for Irregular Areas
The Phi-3.5 Mini Instruct model is a lightweight AI with 3.8 billion units, designed to follow instructions and support 128k token lengths.
This model is ideal for activities that require critical thinking skills in memory- or space-limited environments, including tasks such as coding, solving math problems, and reasoning.
Despite its small size, the Phi-3.5 Mini Instruct model shows a competitive edge in multi-language discussions, which clearly shows a significant improvement from its predecessor.
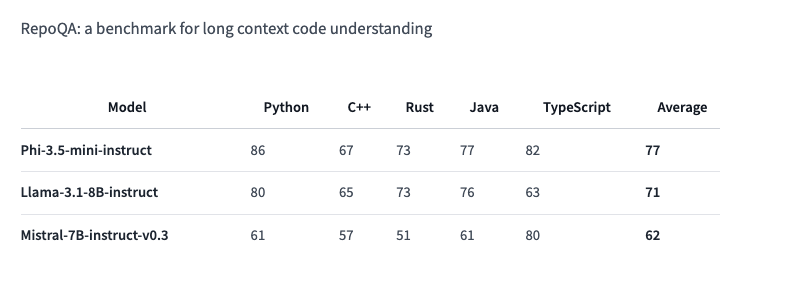
It boasts top scores on several benchmarks and outperforms other similar versions (Llama-3.1-8B-instruct and Mistral-7B-instruct) on the RepoQA benchmark that tests «code understandability.»
Phi-3.5 MoE: Microsoft’s ‘Mixing Experts’
The Phi-3.5 MoE (Mixture of Experts) model appears to be the first in this model class from the company, which combines several different models into one, each performing different functions.
The model supports architectures with 42 billion working units and supports a token length of 128k, providing massive AI performance for targeted applications. However, it works fine with 6.6B units, according to HuggingFace’s documentation.
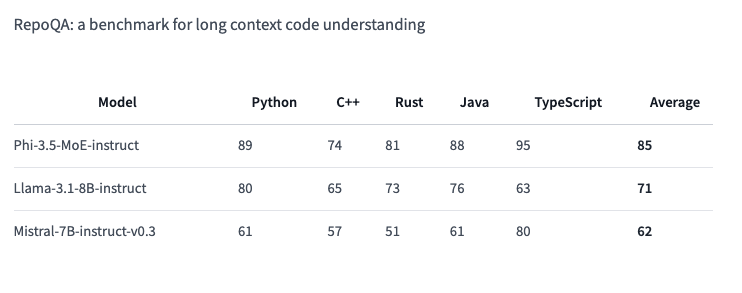
Phi-3.5 MoE is designed to perform well on a wide range of concepts, it offers strong performance in code, math, and multi-language comprehension, often outperforming larger models in other benchmarks, including, RepoQA:
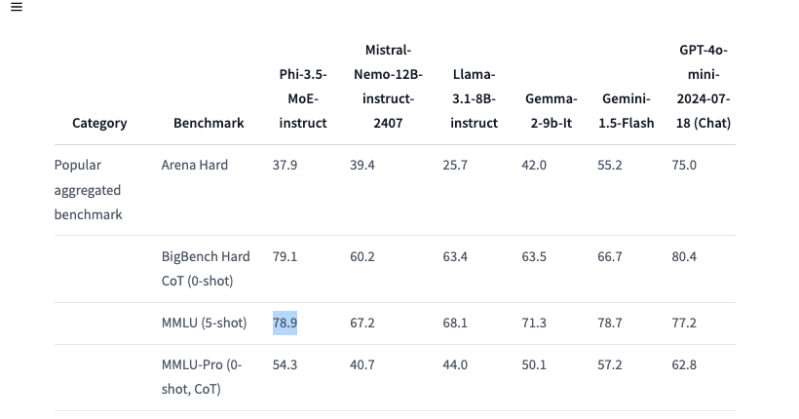
It also impressively beats the GPT-4o mini on the 5-shot MMLU (Massive Multitask Language Understanding) in all subjects such as STEM, humanities, social sciences, in various skills.
The unique design of the MoE model allows it to be optimized and handle complex AI tasks in multiple languages.
Phi-3.5 Vision Instruction: Advanced Multimodal Reasoning
Completing the trio is the Phi-3.5 Vision Instruct model, which combines text and graphics skills.
This multimodal model is particularly suitable for tasks such as image understanding, shape recognition, chart and table understanding, and video summarization.
Like other models in the Phi-3.5 series, Vision Instruct supports up to 128k token lengths, making it capable of handling high-resolution, multi-dimensional tasks.
Microsoft points out that the model was trained with publicly available filters and filters, focusing on high-quality, deep data.
Teaching the new Phi trio
The Phi-3.5 Mini Instruct model was trained on 3.4 trillion symbols using 512 H100-80G GPUs over 10 days, while the Vision Instruct model was trained on 500 billion symbols using 256 A100-80G GPUs over 6 days.
The Phi-3.5 MoE model, which has an expert hybrid architecture, was trained on 4.9 trillion symbols with 512 H100-80G GPUs over 23 days.
Open-source under the MIT License
All three versions of Phi-3.5 are available under the MIT license, demonstrating Microsoft’s commitment to supporting the open source community.
This license allows developers to use, modify, integrate, publish, distribute, license, or sell copies of this software.
The license includes a disclaimer that the software is provided «as is,» without warranties of any kind. Microsoft and other copyright holders shall not be liable for any damages, losses, or other liabilities arising from the use of the software.
Microsoft’s release of the Phi-3.5 series represents an important step in the development of multilingual and multimodal AI.
By providing these models under an open license, Microsoft empowers developers to integrate advanced AI capabilities into their applications, improving both business and research capabilities.
#Microsoft #releases #powerful #versions #Phi3.5 #beating #Google #OpenAI